Watching the old galaxy fade away.
In the dawning decades of our new Digital Age, the news business has shrunk from a galaxy of bright stars to a loose collection of white dwarfs glowing in otherwise dark empty spaces. The empty spaces are called “news deserts.”
In the meantime (at least in the US), the redstream is the new mainstream, while more and more people get news (or what passes for it) from social media and each other. Countless sources are also faked up by AI.
Less metaphorically, the news business has de-institutionalized. How can we re-institutionalize it in digital ways that can also be trusted?
I suggest we start by spinning up News Commons that work with the fewest possible intermediaries between people and sources, and value exchanges that reward everyone.
Some background:::
1) The Dying Galaxy
Here’s how bright stars have turned into white dwarfs:
- Stopped Presses: There are now fewer than 1,000 daily newspapers left in the U.S. Over 50 million Americans now live in news deserts.
- Radio Silence: CBS News Radio—the oldest and most august of all the syndcated broadcast news sources— will be gone in May 2026 after a 99-year run. Meanwhile, Public Radio (NPR et al.) faces a “shrinking pie” problem: ratings (dig around here) remain steady or are growing only because stations hold larger shares of a rapidly dwindling over-the-air audience.
- Cut Cables: Cord-cutting continues, as viewing moves from cable to Internet, and from live to on-demand streamed entertainment. In the midst of this shift, cable news is morphing from mainstream to redstream. Specifically, CNN is moving rightward under the Ellisons, while Fox News stays as right as they were, and MSNBC under its new MS NOW brand continues to glow dimly at the left end of the ratings. None come close in popularity to any of the top news commentary podcasts. Anyway, cable news is transitioning from a collection of leanings (center, left, and right) to highly partisan amen corners with shrinking audiences.
- Thinning Air: Over-the-air TV (what we still call stations, with channel numbers) is now called “linear,” whether it’s from a connected antenna or from a cable screwed into the same jack on the back of a TV. That category is also in decline, a victim of the same viewing shift to streaming services (now less often called over-the-top, or OTT, now that the bottom—linear TV—is fading away).
- Babes in New Woods: News is still being consumed, though it’s hardly hard news or from the media we knew when all the stars were bright and mostly trusted. Especially for young people. Lots of stats at both those links. The bottom line is that none of that flow is from the old stars. At least not directly.
Nearly all coverage of changes in the dimming news galaxy concerns one or more of the five factors listed above. Some of that coverage (most notably from the Nieman Journalism Lab) is about innovations. To mix metaphors a bit, while some of these innovations look like greenfields, none of them look very large. (More credit where due: At least these efforts, as the Quakers say, improve on the silence.)
2) MyTerms (IEEE 7012) and the Agentic Shift
Today, the news world is mostly hidden behind permission walls. Inside those walls, absent personal privacy is exploited to extremes almost nobody will contemplate or admit to. (Here’s a PageXray of Wired.com—one of the “good” guys.) For a fig leaf over the hard-ons walled garden barons have for personal data, visitors knocking on front doors must yield to demands in the form of misleading cookie notices and in crap like this:
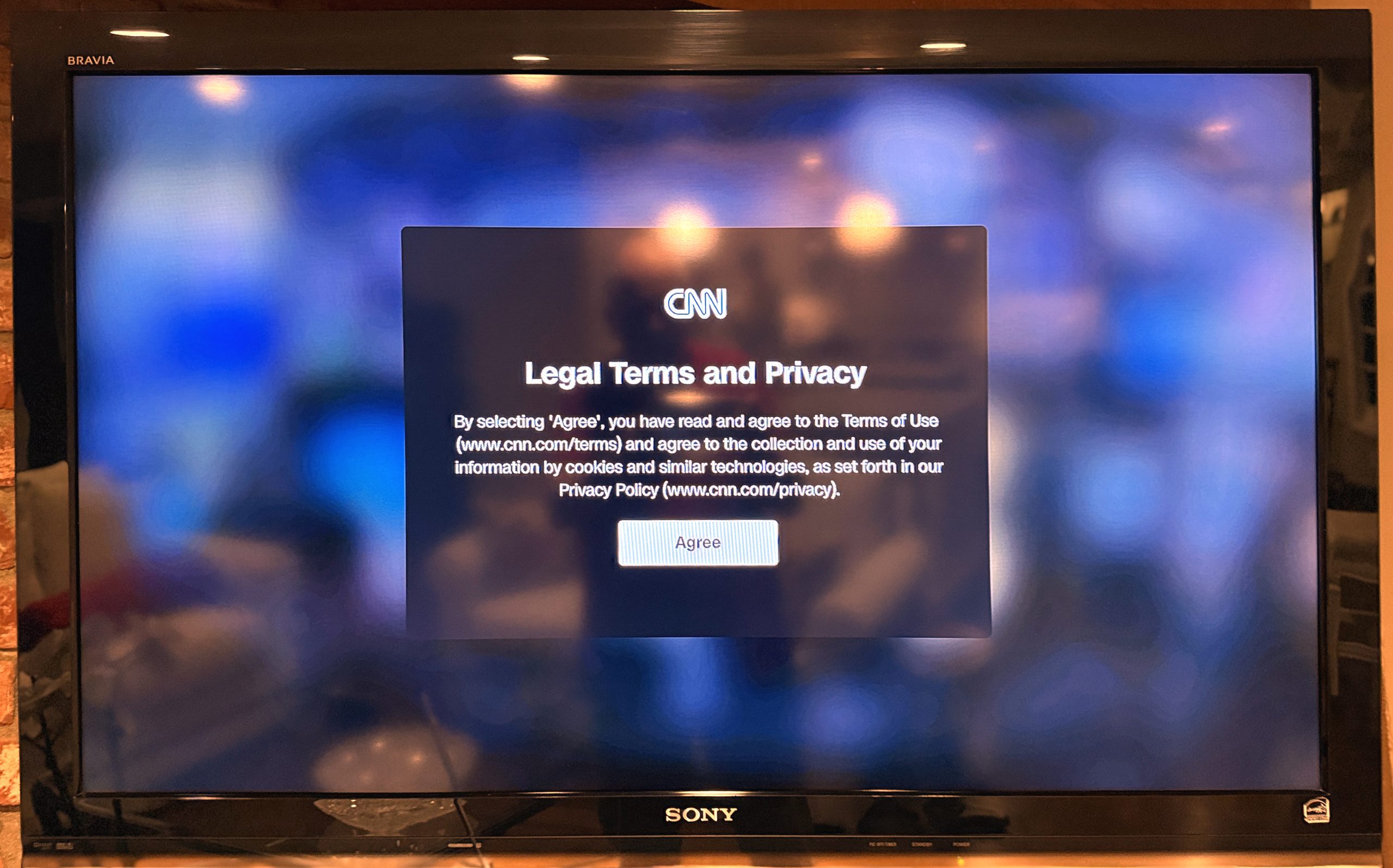
Go to www.cnn.com/privacy, as the notice suggests (or just click on that image), and you will find your privacy well and truly fucked.
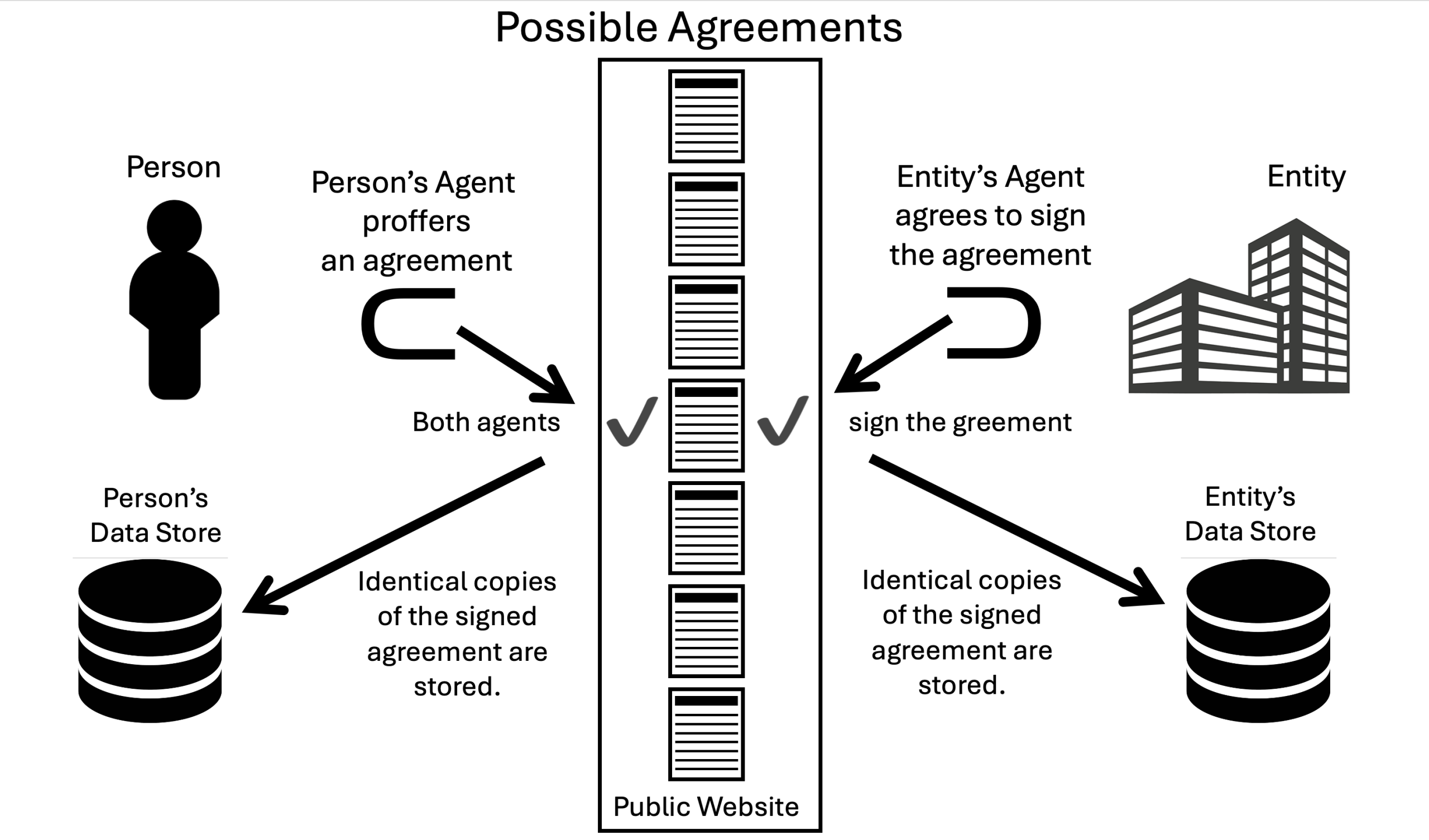
The ProjectVRM community has written a lot about this over many years. But now, thanks to our work with Customer Commons since 2012 and the IEEE since 2017, we have IEEE 7012 (MyTerms): a standard that flips the script on privacy-as-bullshit by giving individuals a way to proffer their own damn privacy terms as binding contracts, with agents working for both parties. Specifics:
- Personal AI Agents: Under MyTerms, individuals operate through agents that can range in complexity from browser plug-ins to private AI agents. These agents have a sole responsibility to the person, proffering and signing agreements, and keeping auditable records of them.
- Reciprocal Agency: On the other side, news providers use their own agents tto choose from the person’s roster of privacy agreement choices (on the Creative Commons model). This machine-to-machine handshake replaces the deceptive, unfair, and un-auditable non-agreements we get with cookie notices and shit such as we see in the image above.
- Unlocked Possibilities: Unlike corporate AI agents designed to keep people inside a walled garden (one cause of the zero-click problem), a personal AI agent can get the requested news item after a MyTerms agreement is signed, and then participate in a whole new value exchange system that works for everyone. For example, should a further agreement be reached (such as one for a micropayment or an acceptable subscription (also built atop MyTerms) the personal AI agent can both obtain the requested news and work out forms of compensation. In this new system, personal data will be shared on an as-needed and trusted basis that continues to assure personal privacy. This can be done in ways that preserve the open Web and create settlement systems that work for all involved (and not just for sellers and the platforms that trapped them in the past).
- Downstream Economic Benefits: When use-value and sale-value are both exchanged on terms that work for all involved, a news ecosystem can be built that rivals the old news galaxy, but with many more bright stars and fewer dark spaces. It will also obsolesce the current all-dwarf system, which is based on customr capture, constant surveillance, and algorithmic guesswork that annoys or offends everyone involved.
3. The New News Commons
To maximize both use-value and sale-value, our goal here is an ecosystem with maximized agency on both sides, and the fewest and simplest intermediaries.
- From redstreams and bluestreams to wide open mystreams: Partisan news at the personal level (look at all those podcasts and blogs) has proven that decentralized, on-demand media are highly resilient. The task now is to multiply and disintermediate both consumption and production. This is required especially at the local level, where realities on the ground (e.g., weather and potholes) tend not to be partisan. What we want here is a common space governed by shared standards (and Ostrom’s principles) rather than algorithmic guesswork by unaccountable giants and their grudging dependents.
- The Nonprofit Pivot: Local digital-first nonprofits now represent over 50% of the Institute for Nonprofit News (INN), providing a model for news as a public good.
- The New Frontier: When you zero-base service and business models on agreed-upon privacy that starts with personal agency and respect for it, anything is possible. (By the way, this is what we’ve had in the natural world since we traded stones for fish. Just because we are still as naked on the Net as we were in Eden doesn’t mean we can’t clothe ourselves and get on with business.)
| Feature | Dying Star News System | Bright Star News Commons |
|---|---|---|
| Privacy | Corporate “consent” (tracking) | MyTerms (User-Proffered Contract) |
| Agency | Dependent “users” | Independent readers, listeners, and viewers with loyal agents |
| Distribution | Centralized walled gardens with paywalls and coerced subscriptions | Open and independent consumers and producers creating use-value and sale-value exchanges that reward both sides |
I could go on, but I want to get this up before I get on another airplane. Meanwhile, contact me by email (first name at last name dot com) or in the comments with ways to improve this. Thanks!